
 Based on Chatgpt, Claude, Gemini, Gok, Copilot or other language models (LLM), all artificial intelligence has functions that look like magic for most of the world. For those who dominate the kitchen a little more, these vehicles are a great help. For those who are in the job, these are actually a black box. In fact, scientists and researchers do not know exactly how a language model works. However, researchers at Claude’s Creator Anthropic say they have made a serious breakthrough. This discovery is considered a critical step towards making artificial intelligence models safer, transparent and reliable.
Based on Chatgpt, Claude, Gemini, Gok, Copilot or other language models (LLM), all artificial intelligence has functions that look like magic for most of the world. For those who dominate the kitchen a little more, these vehicles are a great help. For those who are in the job, these are actually a black box. In fact, scientists and researchers do not know exactly how a language model works. However, researchers at Claude’s Creator Anthropic say they have made a serious breakthrough. This discovery is considered a critical step towards making artificial intelligence models safer, transparent and reliable.The Undared World of Artificial Intelligence
Although the big language models that form the basis of artificial intelligence today have shown an extraordinary success in understanding and producing human language, the decision -making processes of these models are largely the mystery of the decision -making processes. We can see which commands are given to a model and what kind of responses it produces; However, it is still unclear to understand how these answers are created.
This unknown, leads to trust problems in artificial intelligence practices. It is difficult to predict the tendencies of models to produce incorrect information. In addition, some users can not be fully explained in some cases why the “Jailbreak” techniques applied by some users to overcome security measures.
Anthropic researchers took a big step to analyze this complex structure. Inspired by FMRI technology used to examine the human brain, the team developed a new tool to understand the internal functioning of large language models. This technique reveals which processes of artificial intelligence models are activated by mapping their “brains”.
Researchers who applied this new tool to the Claude 3.5 Haiku model showed that artificial intelligence can make planning and logical inferences even if not conscious. For example, when a poem was given a task of writing, it was observed that the model identified the compatible words in advance and then made sentences in accordance with these words.
Another remarkable finding of the research was the logic structure of language models in multi -lingual work. Instead of using separate components in different languages, the Claude model works using a common conceptual field for all languages. In other words, the model first enters into a reasoning process through abstract concepts and then turns this idea into the desired language.
This finding opens new doors about how multilingual artificial intelligence can be made more efficient. This approach, especially for companies that develop global -scale artificial intelligence solutions, can ensure that models work more consistent and faster.
Why is the opening of the black box important?
 The new analysis tool developed by Anthropic can help to better detect possible safety vulnerabilities by following the decision -making processes of artificial intelligence. This new method has the potential to solve the problem of artificial intelligence to be a “black box .. Understanding which steps of LLMs create a specific response can make it easier to analyze why these models make mistakes. It can also pave the way for developing more effective training methods to strengthen safety measures in artificial intelligence systems and reduce faulty or misleading outputs.
The new analysis tool developed by Anthropic can help to better detect possible safety vulnerabilities by following the decision -making processes of artificial intelligence. This new method has the potential to solve the problem of artificial intelligence to be a “black box .. Understanding which steps of LLMs create a specific response can make it easier to analyze why these models make mistakes. It can also pave the way for developing more effective training methods to strengthen safety measures in artificial intelligence systems and reduce faulty or misleading outputs.On the other hand, according to some experts, this mysterious structure of LLMs is not a very big problem.
 As people, we cannot really understand what someone else thinks, and in fact psychologists say that we don’t even understand how our own thoughts work, and that we have made up logical explanations after the event to justify the actions we have done because of the emotional reactions that we are not intuitive or largely aware of. However, in general, it seems true that people tend to think in similar ways and when we make mistakes, it is true that these mistakes somehow enter familiar patterns. This is the reason why psychologists are good in their work.
As people, we cannot really understand what someone else thinks, and in fact psychologists say that we don’t even understand how our own thoughts work, and that we have made up logical explanations after the event to justify the actions we have done because of the emotional reactions that we are not intuitive or largely aware of. However, in general, it seems true that people tend to think in similar ways and when we make mistakes, it is true that these mistakes somehow enter familiar patterns. This is the reason why psychologists are good in their work.However, the problem with large language models (LLMs) is that the methods of accessing outputs are quite different from the way people do the same tasks. Therefore, they can make mistakes that a person is unlikely to do.
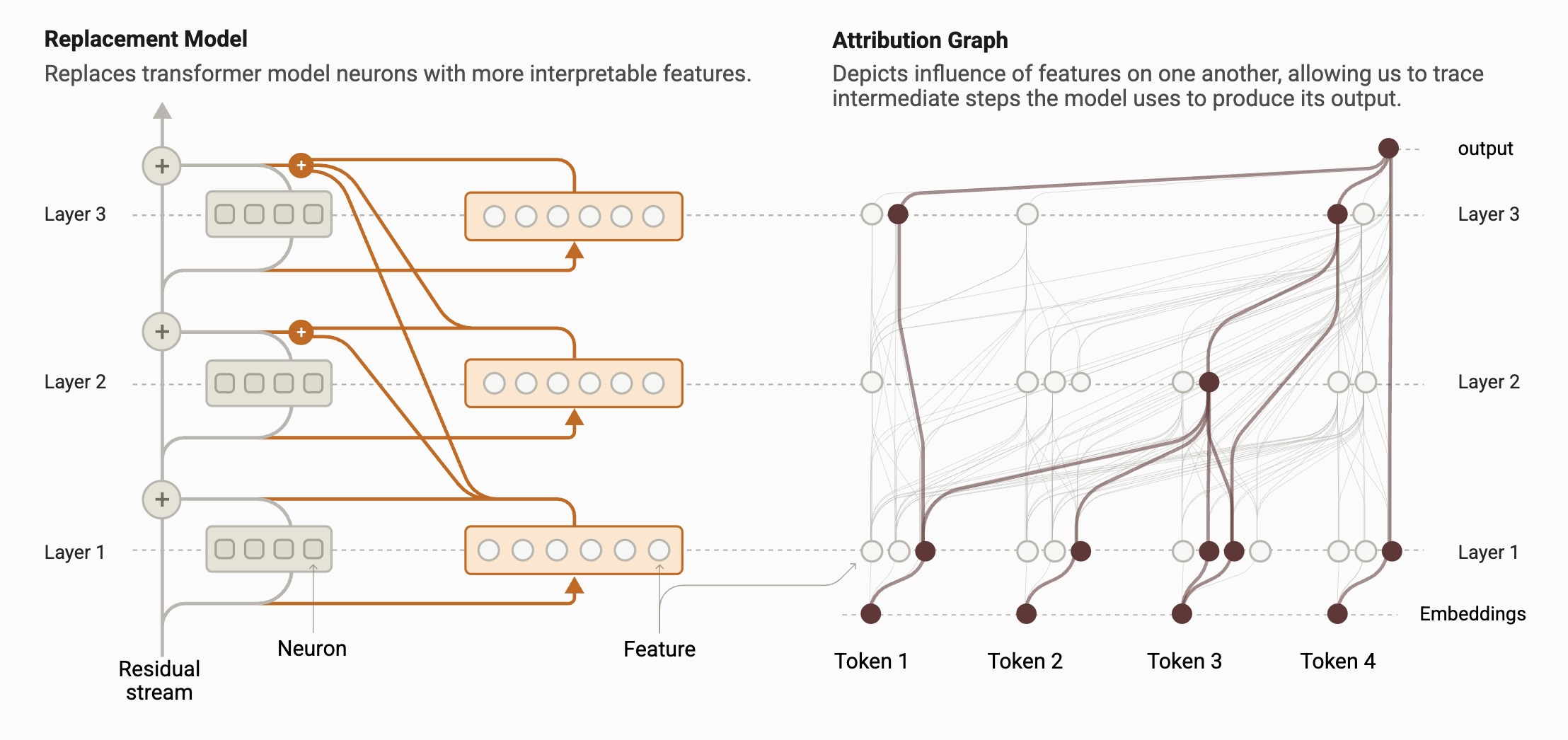
Cross-Layer Transcoder (CLT) Approach
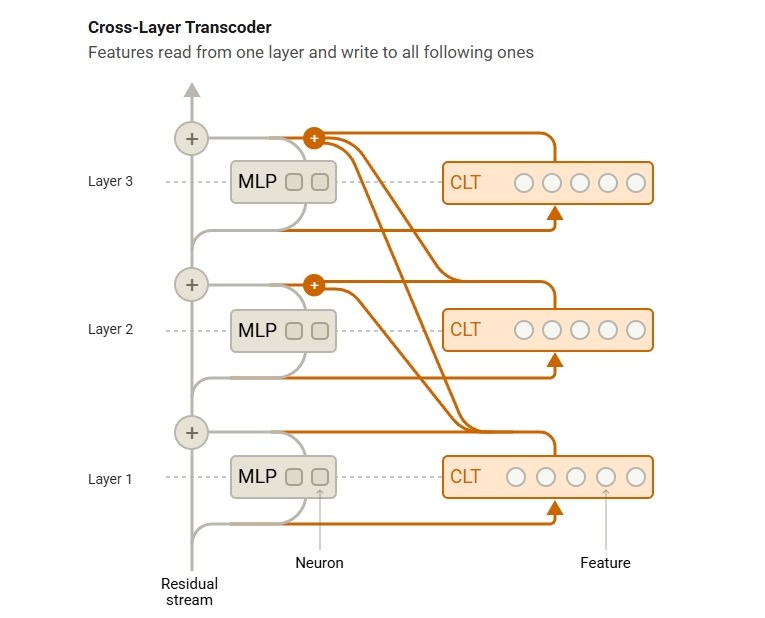 Previous LLM analysis methods were based on examining individual neurons or small neuron groups. Alternatively, the “ablation” technique based on observation of how it works by removing some layers of the model was also used. However, these methods were inadequate to understand the general thinking process of the model.
Previous LLM analysis methods were based on examining individual neurons or small neuron groups. Alternatively, the “ablation” technique based on observation of how it works by removing some layers of the model was also used. However, these methods were inadequate to understand the general thinking process of the model.Anthropic has developed a completely new model to overcome this problem: Cross-Layer Transcoder (CLT). The CLT analyzes the artificial intelligence model at the level of interpreted features, not at the level of individual neuron levels. For example, all the shootings of a particular verb, or all terms, which mean “more”, can be considered as a single set of features. In this way, researchers can see which neuron groups work together while performing a particular task of the model. In addition, this method provides researchers the opportunity to follow the reasoning process of the model throughout the layers of neural network.
 However, Anthropic also pointed out that the method has some limitations. This technique offers only one predictions of what is actually happening in a complex model (eg Claude). In addition, some neurons that are except the circuits detected by the CLT method and play a critical role in the outputs of the model may be overlooked. In addition, he cannot capture the mechanism of “Attention”, one of the main working principles of large language models. This mechanism allows the model to give importance to different parts of different parts of the input text and to change this importance as a dynamic change. The CLT method cannot capture this shifts, and these shifts may play an important role in the “thinking” process of the model.
However, Anthropic also pointed out that the method has some limitations. This technique offers only one predictions of what is actually happening in a complex model (eg Claude). In addition, some neurons that are except the circuits detected by the CLT method and play a critical role in the outputs of the model may be overlooked. In addition, he cannot capture the mechanism of “Attention”, one of the main working principles of large language models. This mechanism allows the model to give importance to different parts of different parts of the input text and to change this importance as a dynamic change. The CLT method cannot capture this shifts, and these shifts may play an important role in the “thinking” process of the model.Anthropic also stressed that analyzing the circuits of the network is quite time -consuming. Even for short inputs consisting of “dozens of words”, he can take a few hours of a human expert. How the method can be scaled to much longer inputs remains unclear. However, CLT is an extremely important step to open Pandora’s box.



