
 “Does GPT-4 Pass the Turing Test?” In a preprint research paper titled , two researchers from UC San Diego pitted OpenAI’s GPT-4 AI language model against human participants, GPT-3.5, and ELIZA, to see which was better at tricking participants into believing it was human. But the non-peer-reviewed study found that human participants correctly identified other people in only 63 percent of interactions, outperforming the artificial intelligence model of a computer program from the 1960s that powers the free version of ChatGPT.
“Does GPT-4 Pass the Turing Test?” In a preprint research paper titled , two researchers from UC San Diego pitted OpenAI’s GPT-4 AI language model against human participants, GPT-3.5, and ELIZA, to see which was better at tricking participants into believing it was human. But the non-peer-reviewed study found that human participants correctly identified other people in only 63 percent of interactions, outperforming the artificial intelligence model of a computer program from the 1960s that powers the free version of ChatGPT.British mathematician and computer scientist Alan Turing first introduced the Turing test in 1950 under the name “The Imitation Game”. It has since become a famous but controversial criterion for determining a machine’s ability to imitate human speech. In modern versions of the test, a human judge typically speaks to either another human or a chatbot without knowing which is which. If the judge cannot reliably distinguish the chatbot from the human to a certain extent, the chatbot is said to have passed the test. The threshold for passing the test is subjective, so there has never been broad consensus on what would constitute a passing success rate.
ChatGPT lost to ELIZA
 In the study, published on arXiv in late October, UC San Diego researchers Cameron Jones and Benjamin Bergen created a website called turingtest.live and conducted a two-player Turing test to see how well GPT-4 could convince people that they were human when stimulated in different ways. They implemented the application online.
In the study, published on arXiv in late October, UC San Diego researchers Cameron Jones and Benjamin Bergen created a website called turingtest.live and conducted a two-player Turing test to see how well GPT-4 could convince people that they were human when stimulated in different ways. They implemented the application online.Through the site, human interrogators interacted with a variety of “AI witnesses” representing either other humans or AI models that included the aforementioned GPT-4, GPT-3.5, and ELIZA, a rule-based speech program from the 1960s. Random roles were assigned to everyone who participated in the test. In the test, witnesses were instructed to convince the interrogator that they were human. The players matched with the artificial intelligence models were always in the role of interrogator.
It is stated that 652 participants completed a total of 1,810 sessions in the experiment and 1,405 games of them were analyzed. Surprisingly, ELIZA, developed by computer scientist Joseph Weizenbaum at MIT in the mid-1960s, scored relatively well, achieving a 27 percent success rate during the study. GPT-3.5 achieved a success rate of 14 percent, below ELIZA, depending on the question. GPT-4 achieved a success rate of 41 percent, second only to real humans.
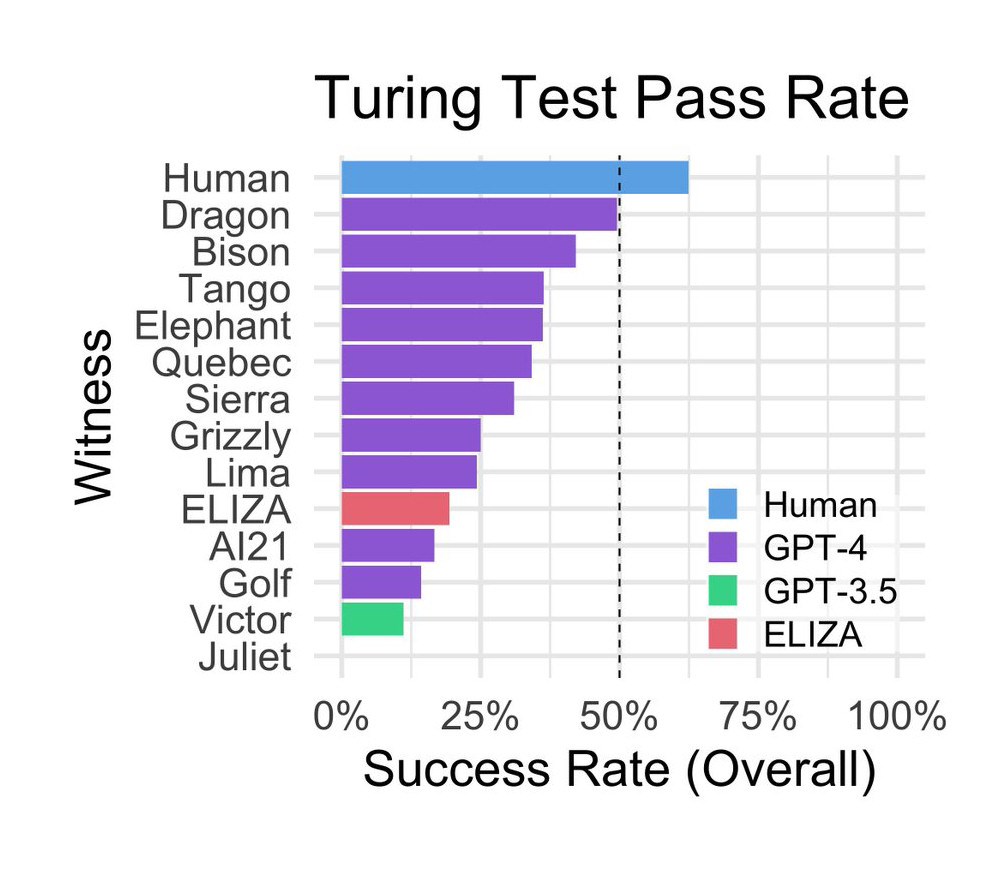 GPT-3.5, the underlying model behind the free version of ChatGPT, was specifically conditioned by OpenAI not to present itself as a human, which may partly explain its poor performance.
GPT-3.5, the underlying model behind the free version of ChatGPT, was specifically conditioned by OpenAI not to present itself as a human, which may partly explain its poor performance.Frequently used strategies during the sessions included small talk and questioning. Evaluations based on linguistic style and socio-emotional characteristics were effective in shaping participants’ decisions. Additionally, the study shows that education level and familiarity with language models are not decisive in detecting AI.
GPT-4 also fails
As a result, the study authors concluded that GPT-4 did not meet the success criteria of the Turing test, neither achieving a 50 percent success rate (higher than a 50/50 chance) nor exceeding the success rate of human participants.
Researchers think that with the right stimulus design, GPT-4 or similar models could eventually pass the Turing test. But the real challenge lies in designing a cue that mimics the subtleties of human speech styles. Like GPT-3.5, GPT-4 is conditioned not to present itself as human.
On the other hand, in the sessions, people were not convinced that a real person was real, even though they were in front of them, or in other words; people could not prove that they were human. This may reflect the nature and structure of the test and the expectations of the jury members rather than the nature of human intelligence. Researchers also state that some people engage in “trolling” by pretending to be artificial intelligence.



